PDE-constrained optimization provides a rigorous framework for optimizing functionals subject to partial differential equation (PDE) constraints. It is one of those techniques that appears deceptively simple from a distance but actually becomes increasingly subtle and complicated once you dive into the details. It is one of the greatest tools that modern computational science has to offer, yet few people truly understand the underlying mathematics and complexity. While PDE-constrained optimization is most commonly associated with shape and topology optimization, its potential for control, design, and yield optimization in physical and chemical systems is, in my view, significantly underappreciated.
In this blog post I explain the mathematics of PDE-constrained optimization in detail, with a special focus on the adjoint method for calculating gradients of the objective function. I also demonstrate an implementation using FEniCS and dolfin for maximizing the yield of a gaseous $\text{CO}_2$ to $\text{O}_2$ reactor.
The Variational Formulation
Let’s start from a time-independent partial differential equation
\[\mathcal{F}(u,p) = 0, \qquad x \in \Omega \subset \mathbb{R}^d \tag{1}\]where $u(x)$ is the solution and $p \in \mathbb{R}^m$ is a set of parameters. We will assume that any forcing terms and boundary conditions have already been incorporated in this formulation. Time-independence is not strictly necessary — one might be interested in minimizing the maximal value of $\lVert u(x,t)\rVert$ over $t$ — but it does make the upcoming derivation somewhat easier.
In most situations, the PDE is already discretized prior to optimization. Let $x = {x_i}_{i=1}^N \in \mathbb{R}^{dN}$ be the nodes or grid points and $u = (u(x_1), u(x_2), \dots, u(x_N)) \in \mathbb{R}^{dN}$. Then the condition that the PDE must be satisfied in the grid points becomes
\[F(u,p)=0, \tag{2}\]where $F:\mathbb{R}^{dN}\times\mathbb{R}^m\to\mathbb{R}^{dN}$ is a nonlinear function. It is very common to use PDE-constrained optimization in conjunction with the finite element method, in which case equation (2) coincides with the weak form of the PDE. The objective is to optimize a scalar functional $J(u,p): \ \mathbb{R}^{dN}\times\mathbb{R}^m\to\mathbb{R}$ of the solution $u$ and the parameters $p$. I will focus on minimization, but maximization can be treated equivalently. We solve
\[\begin{aligned} \min_{u,p} & \ J(u,p) \\ \text{s.t.} & \ F(u,p)=0 . \end{aligned} \tag{3}\]Note that we can already make a simplification here. For a given parameter value $p$, the PDE has only one solution (in theory, multiple solutions are possible near folds or bifurcation points, in which case the solution is unique locally). This means it is possible to write the solution as a function $u=u(p)$. The constrained problem (3) reduces to
\[\min_p \ J(u(p),p) = \min_p f(p), \tag{4}\]and the optimum occurs whenever
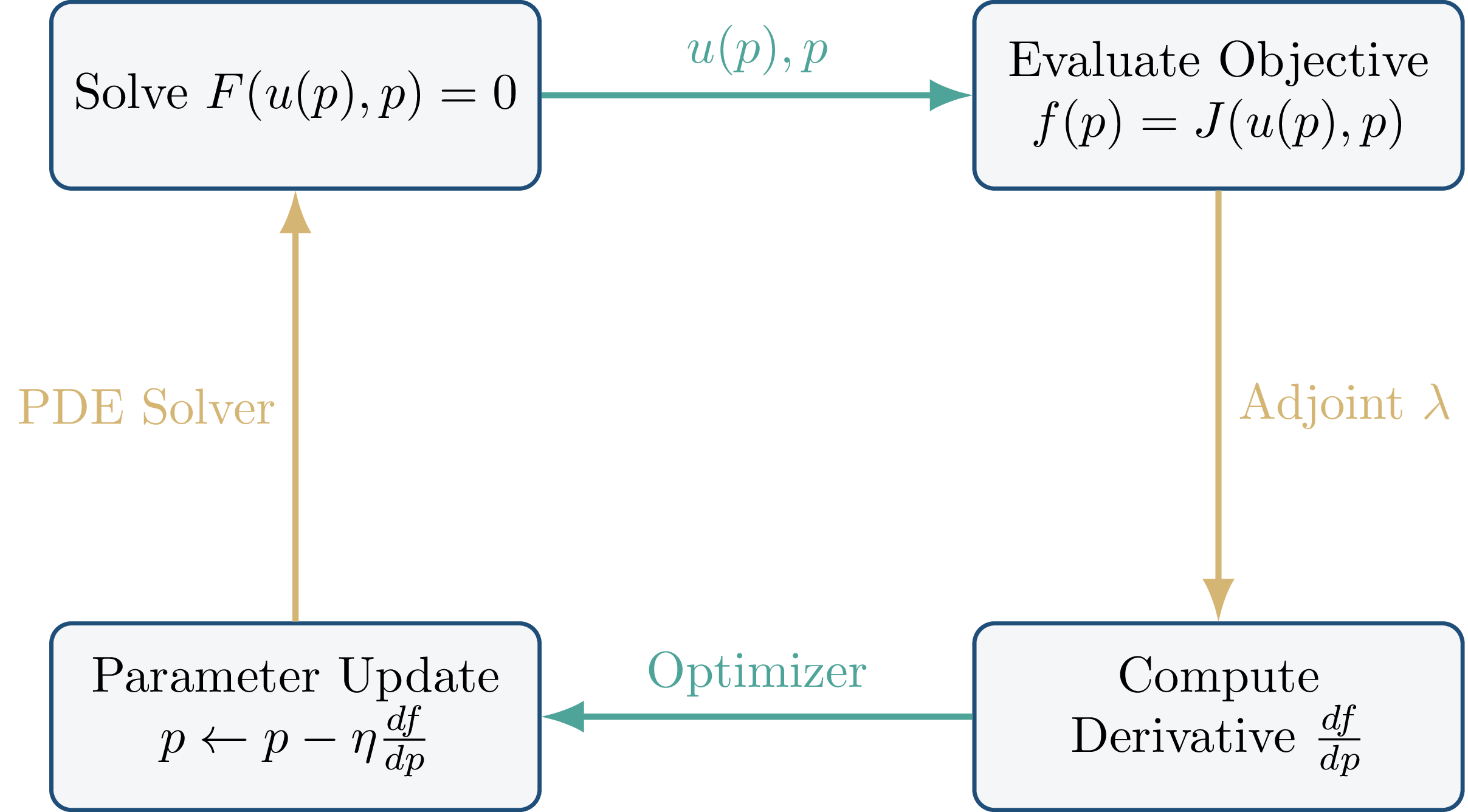
\[\frac{df}{dp}(p)=0. \tag{5}\]The reduction from a constrained to an unconstrained formulation simplifies the optimization procedure a lot. Given the current parameter guess $p_n$, we:
- Solve the discrete PDE $F(u,p_n)=0$ for $u(p_n)$;
- Evaluate $f(p_n)=J(u(p_n),p_n)$;
- Somehow compute the gradient $\frac{df}{dp}(p_n)$;
- Pass the objective and its gradient to an optimizer to compute $p_{n+1}$.
This is all there is to PDE-constrained optimization: a gradient-based optimizer running on top of a PDE solver. Typical choices are Newton, (L-)BFGS, or gradient descent (often with Adam).
The Adjoint Method
The hard part is computing the gradient
\[\frac{df}{dp} = \frac{\partial J}{\partial u}\frac{du}{dp} + \frac{\partial J}{\partial p}. \tag{6}\]Here, $\partial J/\partial u \in \mathbb{R}^{Nd}$ is a row vector of partial derivatives of the objective with respect to the solution, and $\partial J/\partial p\in\mathbb{R}^m$ is usually easy to compute The difficult term is the Jacobian
\[\frac{du}{dp} \in \mathbb{R}^{Nd\times m}, \tag{7}\]which measures how the PDE solution changes with the parameters. There are two main approaches to computing such sensitivities: automatic differentiation (AD) and finite differences. Most large-scale legacy PDE solvers are not compatible with AD, especially when they rely on black-box solvers or iterative linear algebra routines. Differentiable PDE solvers are a very recent research topic.
As a result, one typically resorts to finite differences. The idea is to perturb each component of $p$ by $\varepsilon e_i$ and solve the PDE:
\[F(u(p+\varepsilon \ e_i),p+\varepsilon \ e_i)=0.\]Then the $i$-th column of the Jacobian is approximated by
\[\frac{du}{dp}(:,i) \approx \frac{u(p + \varepsilon \ e_i)-u(p)}{\varepsilon}.\]This is extremely expensive: it requires solving the PDE $m$ times. Since the PDE solve is usually the computational bottleneck, this approach quickly becomes impractical.
The Lagrangian
Fortunately, we do not need the full Jacobian $du/dp$ — only its action on $\partial J/\partial u$. Since $F(u(p),p)=0$ for all $p$, differentiating with respect to $p$ gives
\[\frac{\partial F}{\partial u}\frac{du}{dp} + \frac{\partial F}{\partial p} = 0,\]or equivalently,
\[\frac{\partial F}{\partial u}\frac{du}{dp} = -\frac{\partial F}{\partial p}. \tag{8}\]Substituting into (6) yields
\[\frac{df}{dp} = -\frac{\partial J}{\partial u} \left(\frac{\partial F}{\partial u}\right)^{-1} \frac{\partial F}{\partial p} + \frac{\partial J}{\partial p}. \tag{9}\]This expression is still problematic because it involves the inverse of the PDE Jacobian. To avoid this, we introduce the Lagrangian
\[\mathcal{L}(u,p,\lambda) = J(u,p) - \lambda^T F(u,p), \tag{10}\]where $\lambda\in\mathbb{R}^{Nd}$ is the adjoint variable. A classical result from optimization theory is that critical points of $\mathcal{L}$ correspond to critical points of $J$ under the PDE constraint.
Taking the derivative with respect to $u$ gives the KKT condition:
\[\frac{\partial \mathcal{L}}{\partial u} = \frac{\partial J}{\partial u} + \lambda^T \frac{\partial F}{\partial u} = 0 \Rightarrow \frac{\partial J}{\partial u} = -\lambda^T\frac{\partial F}{\partial u}. \tag{11}\]Plugging this into (9) leads to a remarkable simplification:
\[\frac{df}{dp} = \lambda^T \frac{\partial F}{\partial p}+\frac{\partial J}{\partial p}. \tag{12}\]The expensive inverse has vanished. We now have a gradient formula depending only on how $F$ and $J$ depend on $p$.
The Adjoint Equation
We still need to compute $\lambda$. From (11) we obtain the adjoint equation:
\[\left(\frac{\partial F}{\partial u}\right)^T \lambda = -\left(\frac{\partial J}{\partial u}\right)^T. \tag{13}\]This is a linear system with the same dimension as the original PDE discretization. It is usually well-posed and can be solved with standard numerical linear algebra techniques.
In summary, PDE-constrained optimization proceeds in four steps:
- Solve the primal PDE for $u(p)$.
- Solve the adjoint PDE (13) for $\lambda$.
- Compute the gradient using (12).
- Update $p$ with any gradient-based optimizer.
This makes adjoint methods dramatically more efficient than finite differences when $m$ is large. These steps are also shown on Figure 1.
A Note on Implementation
The main computational challenge is forming the adjoint matrix $\left(\partial F/\partial u\right)^T$. Once it is available, solving the adjoint system is routine.
Modern finite element libraries like FEniCS can construct this matrix automatically using algorithmic differentiation (“taping”). This is one of the reasons FEniCS has become a standard tool for PDE-constrained optimization.
Conclusion
PDE-constrained optimization is one of the most powerful tools in modern computational science. From wind turbine blades to airplane wings to chemical reactors, many engineering problems can be formulated within this framework — yet the underlying mathematics is often underappreciated.
This post provided a compact mathematical explanation of the adjoint method for efficient gradient computation. I hope you found it useful for your work.